내가 만든 COOKIE~~ : client와 server 간의 상호작용
앞서 2-2-1ㅇ, HTTP server은 stateless라고 말했다.
- 이 말은, multi-step으로 구성된 Web transaction을 수행한다고 해도, 각 메시지는 독립적으로 처리된다는 것이다.
- 이러한 방식은, multi-step transaction에서 실패하거나 중단되는 경우에도 복구할 필요가 없다는 장점이 있다.
- 밑의 사진은, stateful protocol의 동작 방식이다. 그런데, 만약 이러한 과정 중간에 client crash가 발생해 통신이 끊긴다면, 처음부터 다시 시작해야 하기에 복잡한 상황이 연출된다.

아무리 HTTP를 사용하더라도,
서버가 사용자 접속을 제한하거나 사용자에 따라 콘텐츠를 제공하기 원하므로
사용자를 확인하는 것이 바람직할 때가 있는데, 이때 HTTP는 쿠키(cookie)를 사용한다.
쿠키의 구성요소는 총 4가지가 있다.
- Cookie header line
- HTTP response message에 존재하는 부분이다.
- Set-Cookie: sessionId=abc123; Path=/
- 위와같은 형태로 클라이언트 브라우저에 포함되어, 추후 서버와의 통신에 사용된다.
- Cookie header line in next HTTP request message
- 만약 같은 서버와 통신을 또 한다면, 쿠키가 자동으로 request message에 포함된다.
- Cookie: sessionId=abc123
- 서버는, 이 쿠키를 통해 client를 식별할 수 있다.
- Cookie file ( kept on user’s host, managed by user’s browser)
- 쿠키는 사용자의 컴퓨터에 쿠키 파일로 저장되며, 브라우저가 이를 관리한다.
- Back-end Database at Website
- 서버는 쿠키 정보를 기반으로 DB를 조회해, 관련 데이터를 조회할 수 있다.
구체적인 동작 예시는 아래와 같다.

구체적인 동작 과정을 살펴보자.
- 웹 서버에 HTTP 요청을 보낸다.
- 서버는 unique한 식별 번호를 만들고, DB에 엔트리로 식별번호를 인덱싱한다.
- HTTP 메시지에 Set-cookie: 식별번호 를 함께 포함시켜 request msg를 보낸다
- 브라우저는 헤더를 보고, 관리하는 쿠키 파일에 그 라인을 덧붙인다.
- 다시 동일 웹 서버에 요청을 보낼 때 브라우저는 쿠키 파일을 참고하고, 이 사이트에 대한 식별번호를 발췌하여 Cookie_ : 식별번호의 헤더를 요청과 함께 보낸다.
→ 그렇다면, 쿠키는 어떤 목적으로 사용될까?
- Authorization
- 로그인을 했을 때의 인증상태를 기억해 페이지를 이동할 때마다 로그인을 할 필요가 없게함
- Shopping cart
- 장바구니 담은 물건 기억하기
- Recommendation
- 사용자 맞춤 제품 추천
- User Session state
- web e-mail에서 쿠키를 통해 그 세션에 계속 연결된 상태로 유지 가능
→ 프로토콜 엔드포인트: 서버와 클라이언트는 여러 트랜잭션(여러 요청과 응답)이 이루어지는 동안 state를 유지해야 해 이를 위해 클라이언트와 서버가 서로 어떤 상태에 있는지 기억하는 게 중요한데, 이 역할을 쿠키가 해 주는 것이다.
→ but 쿠키를 통해 개인정보를 수집해 악용하는 사례도 있을 수 있음.
Web Caching (Proxy servers)
웹 캐시(cache)(프록시(proxy) 서버)는 기점 웹 서버를 대신하여 HTTP 요구를 충족시키는 개체이다.
캐시는 client와 server의 역할을 둘다 할 수 있다.
- Server : 요청한 requeset를 처리
- client : 원본 서버에 대한 클라이언트 역할로, 새로운 / 갱신된 콘텐츠를 캐싱해옴
→ 보통 ISP에 의해서 설치됨
우선, 웹 캐싱이 왜 필요한지 알아보자.
- Client request에 대한 response time을 reduce시킬 수 있다.
- cache가 client랑 가까움
- 또한, 요청을 보내려는 institution에 대한 traffic을 줄일 수 있다.
- 인터넷의 다양한 곳에 캐시가 존재하므로, 캐시를 통해 자원이 부족한 content provider가 더 효율적으로 content를 제공할 수 있도록 돕는다.
- 작은 웹사이트나 서버 자원이 부족한 사이트들도 캐시 덕분에 효율적으로 데이터 전달 가능
그럼, 아래의 사례를 들어 캐싱의 퍼포먼스를 평가해보자.

- 우선, Access link의 전송률은 1.54 Mbps이다.
- 그리고, institutional Router에서 server의 RTT = 2 sec라고 하자.
- clinet가 요구하는 web object size = 100k bits이고,
- browser가 origin server에 요구하는 초당 객체는 15개이다.
- 즉, average data rate to browsers = 15 x 100k bits = 1.5Mbps이다
→ 이때의 Performance를 평가해보자
- LAN Utilization = 0.0015이다. (1.5Mbps/ 1Gbps )
- Access link utilization = 0.97이다 ( 1.5Mbps /. 1.54 Mbps )
- end-end delay = 2 sec + access link delay( minutes ) + LAN delay (usecs 거의 없다고 가정)이다.
만약, 여기서 Access link의 전송률을 100배 늘려 154 Mbps로 만든다고 해보자.
- LAN Utilization = 0.0015,
- Access link utilization = 0.0097
- end-end delay = 2sec + msecs + usecs ~= 2sec이다.
- 성능이 굉장히 향상되었지만, Faster access link는 매우 비싸다는 단점이 있다.
그러면 여기에 Web Cache를 도입하여 성능을 평가해보자
→ Web cache는, Hit rate로 0.4를 가진다고 해보자.

- Access link utilization = 0.6 * 1.5Mbps / 1.54Mbps = 0.58 Bbps이다.
- 또한, Average end-end delay = 0.4*(~msecs) + 0.6 * (2.01) ~= 1.2secs로, 성능이 굉장히 향상되었고, 또한 Web cache의 가격도 저렴하므로 더 좋은 것을 알 수 있다.
그런데, 만약 Cache에 저장되어 있는 Object가 origin server로부터 update가 되지 않았다면 어떻게 해야할까
Conditional GET
앞서 말했듯, 웹 캐싱이 사용자가 느끼는 응답 시간을 줄일 수 있지만, 웹 캐시 내부에 있는 복사본이 새 것이 아닐 수 있다는 문제를 야기한다. 복사본이 클라이언트에 캐싱된 이후 원본이 갱신되었을 수 있기 때문이다.
- HTTP는 클라이언트가 브라우저로 전달되는 모든 객체가 최신의 것임을 확인하면서 캐싱해주는데,
이러한 방식을 조건부 GET(conditional GET) 이라고 한다.
- 먼저, 클라이언트가 서버에 HTTP 요청을 보낼 때, 프록시 서버에서 다음과 같이 요청에 If-Modified-Since 헤더를 포함한다.,
If-Modified-Since: <date> ( ex)Wed, 9 Sep 2015 09:23:24 )
이 날짜는 캐시된 버전의 마지막 수정 시간을 의미한다.
- 이 날짜 이후로 객체가 수정되지 않았다면, 서버로부터 다음과 같은 답변이 돌아온다.
HTTP/1.1 304 Not Modified
Date: Sat, 10 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
(empty entity body)
- 만약 이 날짜 이후로 객체가 수정되었다면, 서버로부터 변경된 Object와 함께 다음과 같은 답변이 돌아온다.
HTTP/1.0 200 OK
<data>
HTTP2
- 전에, HTTP 1.1은 , 1.0과 달리 하나의 TCP connection을 연결해놓으면, clinet의 여러 요청을 단일 TCP 연결을 통해 해결할 수 있는 장점이 있었다.
- 이때 FCFS 방식으로 client의 요청을 처리하였는데, FCFS방식 때문에 문제가 발생한다.
- Head-of-line(HOL) Blocking 문제 !
- 작은 객체 요청이 먼저 도착하더라도 , 앞의 큰 객체 전송이 끝날 떄 까지 대기해야한다.
- Loss-Recovery 문제
- TCP 세그먼트가 손실되면 재전송이 필요한데,
- 이때 손실된 세그먼트를 복구하는 동안 전체 전송이 지연될 수 있다.
- Head-of-line(HOL) Blocking 문제 !
→ HTTP 1.1에서는,HOL 블로킹 문제를 해결하기 위해 여러 개의 TCP 연결을 병렬적으로 열어서 위 문제를 해결했다.
또한, TCP 연결이 공정하게 bottleneck link를 공유하게 하기 위해, 같은 크기의 대역폭을 공평하게 나누어줬다.
만일 n개의 연결이 bottleneck link를 공유했다면, 대역폭을 각각 1/n씩 사용하게 하는 것이다. 많은 HTTP 1.1 브라우저들은 병렬 TCP 연결을 열고 HOL을 막을 뿐 아니라, 더 많은 대역폭을 사용할 수 있게 되었다.
그렇다면, HTTP2에서는 위와 같은 문제를 어떻게 해결했을까?
- Goal of the HTTP2
- HTTP2의 목적은 바로 multi-object HTTP request 에서 delay를 줄이는 것이다.
- 또한, 웹 페이지를 전송하기 위한 병렬 TCP 연결의 수를 줄이는 것이다.
- 이는 서버에서 소켓의 수를 줄일 뿐 아니라, 목표한 대로 TCP 혼잡 제어를 수행하기 위해 중요하다.
- 하지만, 단일 TCP connection을 지원할 경우에는, HOL bloacking을 피하기 위해 구현된 것이 바로 HTTP2이다.
- Feature of the HTTP2
- 우선, 기존 HTTP 1.1과 호환성은 유지하였다.
- 메서드, 상태코드, 헤더 field 대부분은 동일
- 객체 전송 순서에 대한 flexiblity를 제공한다.
- 클라이언트가 지정한 priority에 따라 동적으로 object를 전송한다.
- 클라이언트가 요청하지 않은 object도 미리 push할 수 있다.
- CSS나 JS를 미리 보내 클라이언트 로딩 속도를 높임
- Framing : 프레임 단위로 object 분할해 HOL 문제 해결하기 위한 frame scheduler 실행
- 우선, 기존 HTTP 1.1과 호환성은 유지하였다.
이 중, 중요한 특성인 Framing에 대해서 더 알아보자.
- HTTP2는 HTTP 메시지를 작은 단위로 나눈 후, 이 프레임들을 interleaving 기법을 통해 전송시킨 뒤, 수신 측에서 제조립한다.
- interleaving : 큰 객체와 작은 객체를 교차 전송하여 작은 객체들이 대기 상태에 빠지지 않도록 하는 기법
예를 들어서, 1 large object와 3 small objects를 전송해야 하는 상황을 생각해보자.

기존에는 위 사진과 같이, large object가 끝날 때 까지 small objects들이 대기 상태에 빠졌다.
하지만 프레이밍 기법을 이용하면, 작은 객체들을 대기 상태에 빠지지 않게 하고도 전송할 수 있다.
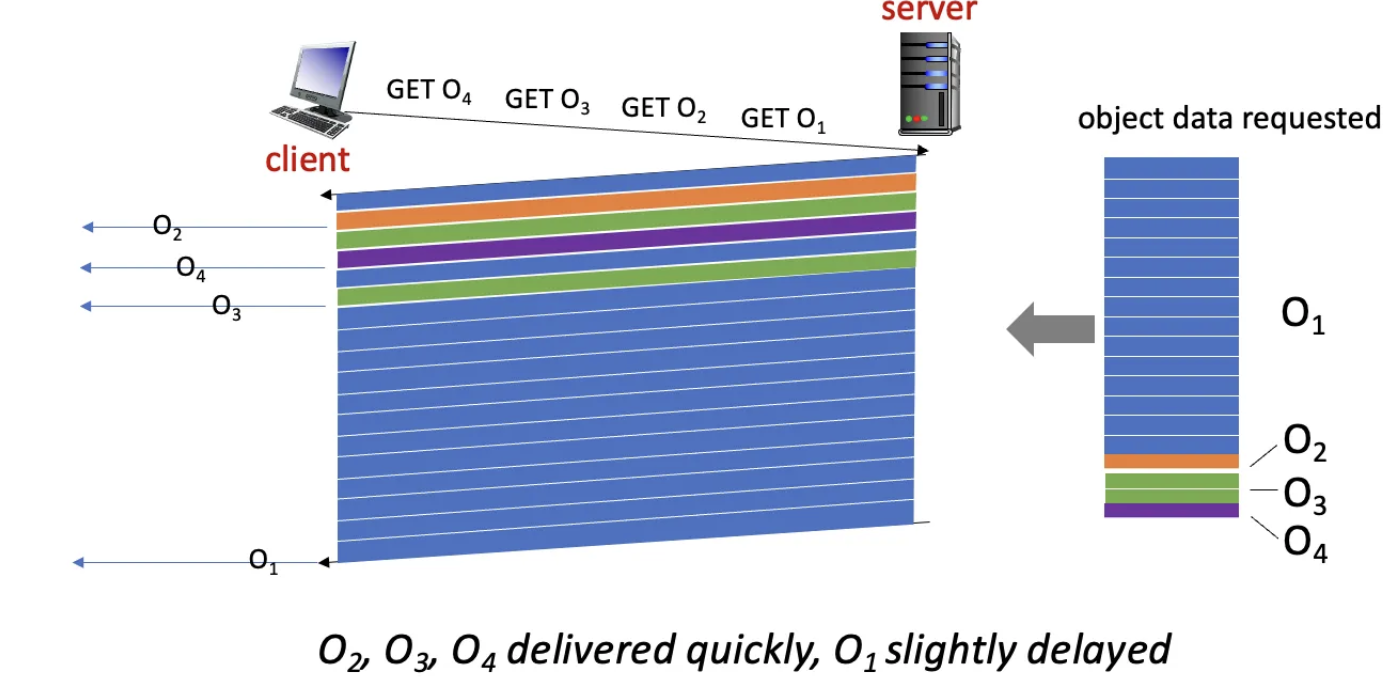
그러나 HTTP2 에도 한계는 존재했다. HTTP2에서는 단일 TCP 연결을 통해서 여러 객체를 교차 전송했지만, 패킷 손실 문제로 인해 전송이 지연됐다.
- TCP는 손실된 패킷을 재전송할 때까지 연결 상의 모든 객체 전송을 중단시킨다.
- 이러한 단점은 HTTP 1.1에서처럼, 병렬적으로 여러 TCP를 연결시켜 전체적인 throughput을 해결하는 방식으로 보완하게 되었다.
- 또한 , TLS 기법을 적용하지 않으면 여전히 security 문제가 발생하였다.
HTTP3에서는 TCP 대신 UDP를 사용하여 더 나은 혼잡 제어, 오류 제어, 보안을 추가하였다.
정리하자면
HTTP 1.0에서는 Non-persistent HTTP로, RTT가 너무 길었음
이를 개선하기 위해, HTTP 1.1에서 Persistent HTTP로, OS overhead 개선
하지만 TCP segment object 개수를 하나로 설정해 놓으니까 HOL 블로킹 문제 발생
→ HTTP 1.1에서는 병렬 TCP 연결로 해결 / HTTP 2.0에서는 framing 기법으로 해결
→ 그러나 framing 과정에서 패킷 손실 발생
→ 이를 해결하기 위해 HTTP 3.0에서 TCP 대신 UDP 사용해 혼잡, 오류를 제어했고 보안 추가
'Computer Network > Ch2) Application layer' 카테고리의 다른 글
| Ch2-5) P2P application (3) | 2024.10.27 |
|---|---|
| Ch2-4) Domane Name System : DNS (1) | 2024.10.27 |
| Ch2-3) Email, SMTP, IMAP (6) | 2024.10.27 |
| Ch2-2-1) Web and HTTP (0) | 2024.10.27 |
| Ch2-1) Principles of internet network (3) | 2024.10.27 |



