그럼, 이번 챕터에서는 전 챕터에서 진행했던 virtual memory 구현 과정에서 Address translation이 어떻게 일어나는지 알아본다.
Address Translation
- 다음 그림은, 간단한 address translation이 일어나는 예시이다.

- %ebx레지지스터의 주소값에 offset으로 0을 더한 값을, %eax 레지스터에 저장한다.
- %eax에 저장된 값에 3을 더한다.
- %eax에 저장된 값을 %ebx의 주소가 가리키는 값에 load한다.
이 과정을 virtual memory 상으로 보면, 다음과 같다.

- 이 전체 과정에서 memory(physical) 접근은 총 5번 일어난다. (Fetch 3번, load / store 각 1번)
Relocation
- OS는 통상적으로 주소가 0이 아닌 다른 공간으로 process를 물리적 공간에 addressing 하고 싶어한다.

모든 Process가 memory 주소가 0인 공간에서 시작할 수는 없기에, 주소를 Relocation하는 과정이 필요하다.
Static Relocation (예전 방법)
- Software-based Relocation으로, OS는 memory에 load하기 전 program을 rewrite한다.
- Static data나 function의 주소값도 변경한다.
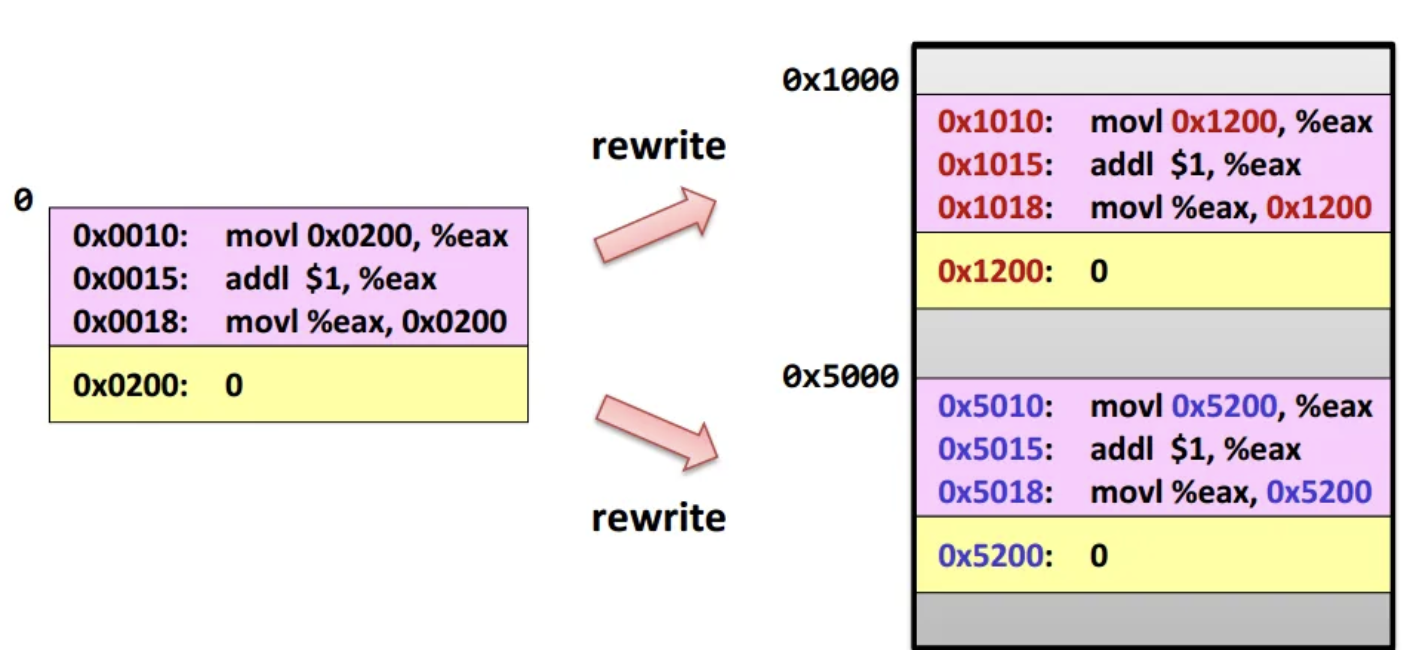
- 장점: Hardware의 개입이 필요하지 않다
- 단점
- Protection이 안된다. (Physical memory에 직접 접근하기 때문)
- 다른 Process가 memory 공간에 접근해 OS나 Process를 파괴할 수 있다.
- Privacy가 없어 다른 memory도 읽을 수 있다.
- 한번 안착되면, address space를 옮길 수 없다.
- 이 때문에 external fragmentation이 발생한다.
- Protection이 안된다. (Physical memory에 직접 접근하기 때문)
⇒ 이러한 단점들을 해결하기 위해서,
Dynamic Relocation
- Harware-based Relocation이다.
- MMU( Memory management unit)이 매 instruction마다 참조할 memory reference의 address translation을 진행한다.
- 만약 virtual address가 invalid 하다면 exception을 호출하면 되기에 protection이 보장된다.
- OS는 MMU에게서 받은 주소값이 타당한지만 검토하면 된다
- 구현방법
- Base
- Base and bound
- Segmentation
- Paging
과 같은 방법이 존재한다. 이들의 구현방법을 알아보기 전에, 먼저 고려해야할 점을 생각해보자.
Design points to consider
- 어떻게 memory protection을 구현할 것인가?
- 구현을 쉽게 하기 위해, 어떤 Hardware의 도움을 받을 것인가?
- Internal, External fragmentation을 어떻게 해결할 것인가?
- 어떤 unit을 공유할 것인가? Shared unit이란 무엇인가?
Fixted partitions (Base)
- Physical memory degree of multiprogramming만큼 partition한다.
- 각 partition의 크기는 고정되어있고, 모두 같다.
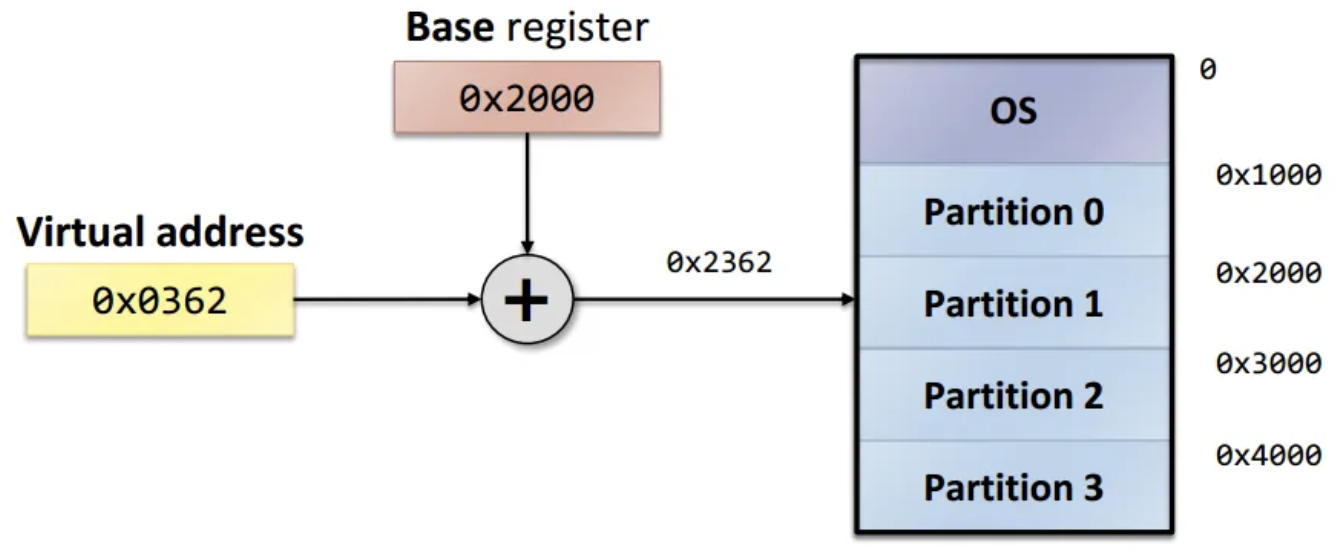
- 이때 Physical address는 Base register에 virtual address값을 더한 주소이다.
- Base register은 OS가 context switch를 하는 과정에서 load된다.
- 장점 : 구현이 간단하고, Context switch가 빠르다
- 단점: Internal fragmentation이 발생할 수 있고, 하나의 Partition size로는 한계가 존재한다.
⇒ 그럼, 여기서 말하는 Fragmentation이란 무엇일까?
Fragmentation
- Definition : 크기가 작아 사용되지 않는 Free memory이다.
- 이런 Fragmentation은 왜 발생할까?
- Free memory는 크기가 작고, 흩어져 있기 때문
- Memory를 allocating하는 규칙상 이 free space는 사용할 수 없기 때문
- 종류는 Internal fragmentation과, External fragmentation이 있음.

Base and Bounds (그럼, Base의 문제였던 Partition을 동적으로 설정하자! )
- Physical memory가, 가변적인 크기의 partitions으로 쪼개진다. (IBM OS와 MVT에서 사용)

- Base 값과 Virtual address값을 더한 것의 주소로 접근하는데, 만약 이게 Bound register의 값보다 작아야 Physical 메모리 접근을 허용하는 방식이다.
- 즉, Bound register의 역할은 Protection임
- 장점
- 간단하고, Cost가 적은 구현이다.
- fixed partition보다 internal fragmentation이 적다.
- 단점
- 각각의 Process가 반드시 physical mem에 연속적으로 할당되어야함.
- External fragmentation 발생
- 만약 사용이 완료된 partition이 release 된다면, external fragmentation 발생
- 이를 완화하기 위해, Compaction 기법이 사용될 수 있음. (Base 값 변경해 E.F 하나로 합치기)
- NO partial sharing : address space의 겹치는 공간을 공유할 수 없음
- Base-and-bounds approach를 구현하기 위해, OS는 다음과 같은 중요한 action을 취해야함.
- Process가 언제 Start running할 것인지 (Partition할당)
- Physical memory에 들어갈 주소 공간을 찾아야 하기 때문
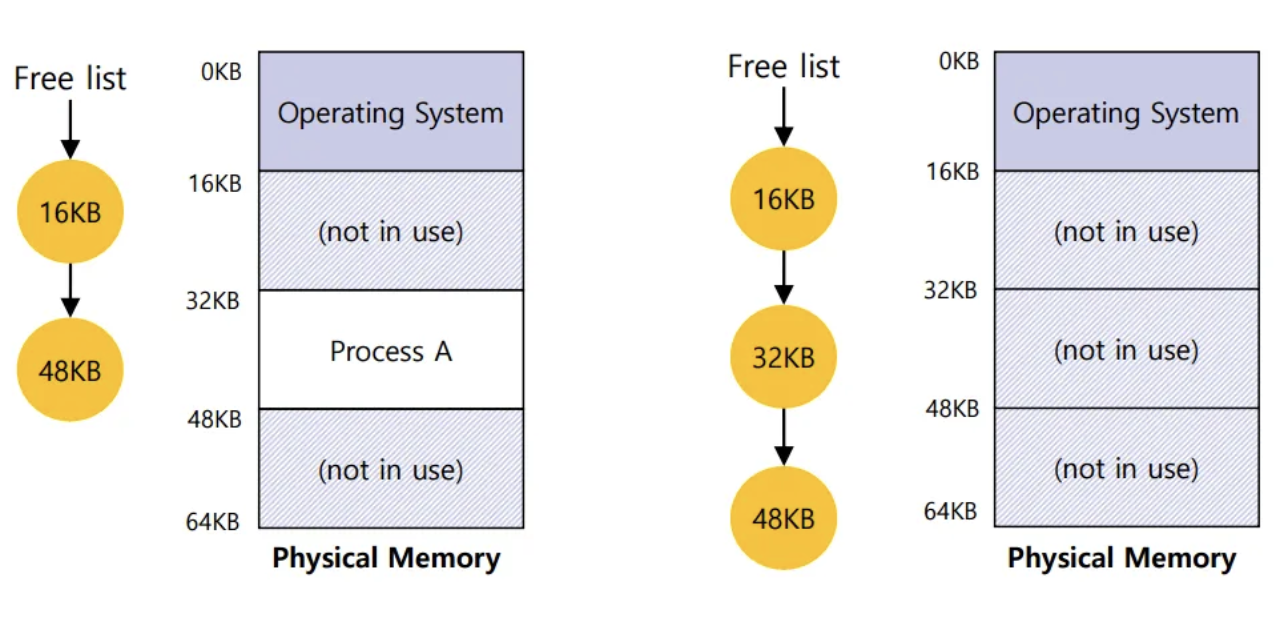
- Free list로 관리 : 사용되지 않는 physical memory의 범위를 linked list로 관리함.
- Process가 언제 Start running할 것인지 (Partition할당)

- Process가 언제 terminated 될 것인지 ( Partition 공간 회수)
- 사용하지 않는 memory 다시 회수 : OS는 free list에 이 memory를 다시 넣어야함
- 진짜 레전드인점. xv6에는 free list 확인하는 함수도 있다.....
- Context Switch가 언제 발생하는지
- base bound를 변경한 값을 PCB에 저장 및 복원해야하기 때문

⇒ 그럼, 이러한 Base-and- bound를 어떻게 Improve 시킬 수 있을까? Compaction !
How to Improve Base and Bounds?
- 일단, 가장 먼저 External fragmentation을 최소화 해야한다.

- Compaction 이용해 Allocated 된 공간을 한쪽으로 모은다. ( But overhead 발생 가능 )
- 그렇다면, Internal fragmentation은 발생을 안하나? 또 그건 아님. 그럼 Internal fragmentation은 어떻게 줄일까?
- Internal fragmentation이라 함은, Virtual memory상의 Big chink of Free space이다.
- 이 또한 physical memory에서 공간을 할당받기 때문에, fragmentation이 발생.
- 또한 위에서 언급했듯, Partial sharing이 불가능함.
- Ex) fork()로 만든 code 공유 불가
⇒ 그럼, PC별로 base bound를 여러개 만들어 각 PC의 heap, code, stack… 위한 조각을 만들면 어떨까?
Segmentation
- Address space를, logical segment로 나눈다.
- 각 segment는 프로그램 구조를 반영하여 Code, stack, heap 등등 논리적 단위로 나누어진다.
- User은 memory를 <segment #, offset>과 같은 형식으로 참조할 수 있다.
- 각 segment는 독립적으로 관리된다.
- Physical memory 상에 따로따로 위치할 수 있다.
- 커지거나, 줄어들 수 있다.
- Protection bit가 존재해 read / write / execute 등등 보호조건을 설정할 수 있다.
- 변수 Partition이 확장된다
- Base and bounds : 1 segment / process
- Segmentation : many segments / process
Segmentation : Addressing
- Explicit approach ( 뭐하는 segment인지 판단하는 것 )
- Virtual address의 일부를 segment number로 활용한다.
- Segment number로 활용하고 남은 bit는 segment의 offset으로 활용한다.

- Implicit approach
- memory 참조의 type에 따라 segment를 결정
- PC- based의 주소지정 : 현재 실행중인 코드를 가리키므로, code segment라고 판단
- SP or BP based의 주소지정: stack 연산에 사용중인 pointer이므로, stack segment라고 판
- memory 참조의 type에 따라 segment를 결정
Segmentation : Implement
- process 당 Segment register이나 table을 보유하고 있다.

- Virtual address의 최상위 bit로 segmentation type을 분류하고, offset과 bounds 의 범위를 통해 접근이 유효한지 확인 후 Base에 offsset 값을 더해 Physical memory에 할당한다.
- 또한, table을 보면 Segment들은 address space 상에서 shared가 가능함을 확인할 수 있다.
- 이러한 code sharing은 현재까지도 사용하는 방법이다.
- 이를 구현하기 위해서, Protection bit가 필요하고, 따라서 추가적인 Hardware의 support가 필요하다.
- 공유하기 위해선, shared segment는 동일한 protection bit를 보유하고 있어야 한다.
- read, write, execute 등 몇몇의 permissions를 위한 bit가 존재한다.
Segmentation : Pros
- address spcae 상에서 부족했던 작은 공간의 할당을 가능하게 해준다.
- Stack과 Heap이 각각 독립적으로 자랄 수 있기 때문이다.
- Segments들을 protect하기 용이하다
- Valid bit와 , 서로 다른 segment에 protection bit을 할당한다.
- ex) code에는 Read-only status, system segment에는 Kernel-mode-only status 배정
- Base and bounds 기법보다 sharing하기 편하다
- Code나 data를 segment level 공유해 메모리 사용을 최적화한다.
- Segment 별로 동적 재배치를 가능하게 external fragmentation을 줄일 수 있다.
Segmentation : Cons
- 각 segment들은 contiguously하게 할당되어야 한다.
- 이 과정에서 External fragmentation이 발생할 수 있음
- 용량이 큰 segment들을 배정하기 위한 충분한 공간이 physical memory에 없을 수 있음.
- Bigger segment table
- Segment table은 main memory에 저장되어야 하기 때문에 overhead가 발생할 수 있다.
- Segment table의 접근 속도를 향상시키기 위해 hardware cache를 사용한다.
- Internal fragmentation
- Heap segment 내의 객체들이 할당 해제되면 Internal fragmentation이 발생한다.
- 동적할당으로 크기 증가 → 사용 다 해서 data release하면 I.F 발생
→ 이러한 단점들을 해결하기 위해, Paging이라는 기법이 탄생하게 되었음 ! 다음챕터에서 계속..